Case Studies - User Stories
I. Data-Driven CRM
Summary: many B2C-companies are interested in an automized and model-free statistical analysis of market research data, that maps the customer's features to features of a purchased product or a service, which allows companies to understand their different types of customers. Because only a model-free approach has the fleibility to cope with upcomming new data with new features.
Keywords: identification of hidden customer groups based on different behavioral trends, development of individual pricing strategies
Description: market research is notoriously difficult. One of the key tasks of modern market research is to deliver data based customer insight. Detailed and in time insights from complaints, sales rates or customer satisfaction are required to constantly update the product features, its price and the customer journey to the changing markets in a repeatable and verifiable way. However:
- The necessary effort in the natural language processing, that is required to algorithmically evaluate Q&A-polls can be tedious, costly or beyond the technical capacities of a company.
- In most cases product ratings and available online data about market niches are mostly either outdated, biased by purchased evaluations, misleading or not properly adapted to the individual use case. Hence these cases the data are useless.
But that is not the only problem: normaly market research should let a company reduce risks if a reliable personalisation of the customer's data-based journey to the product can be realized. So gathering demographic information to better understand opportunities and limitations for gaining customers can be extremely helpful in order to identify barriers that may hinder the customers from purchasing. However there are well known, and not too small hiccups:
- Sometimes tacitly potential customers and markets loose the match with the classical acquisition strategies.
- In other cases some customer features, that have been proven to be strong drivers for purchasing in different cases, can be combined and indicate the existence of a hidden group of new potential customers, that have been not addressed until now - neither by product features nor by marketing. But no one noticed that.
Finally in market research it is found empirically that the search for the ideal price is not about searching for the highest or lowest possible price under certain conditions for the customer. It is more about making margins with some customers, who do not care about the prize, and to go almost without any margins with customers who do. But obviously it is not to be expected, that customers will openly disclose what price they would accept under selected conditions. Normaly that makes individual pricing almost impossible.

As a consequence every company's economic success is dependent on asking a series of simple questions or presenting statements to customers for evaluation their services or purchased product. Particularly online polls based on numbers are short and easy enough, such that customers are willing to answer multiples questions repeatedly. Such polls provide responses in terms of natural numbers, having the data format of an integer and representing the degree of consent. Such data are located on a so-called Likert scale: one star typically indicates least agreement with a poll statement and e.g. nine stars indicate the most agreement.
If additionally the gathered information via such polls includes population data e.g. on age, wealth, family, interests, or anything else that might be relevant for the business, it should be possible to reconstruct a mapping from a selection of customer's features to a successful purchase of a product or a service. The subsequent algorithmic goal will be to identify groups of customers showing the same voting behavior, that has led or has led not to a purchase. This grouping will allow conclusions about beneficial updates of product features, product differentiation or design changes of the marketing strategies in order to avoid annoying customers and to increase the marketing efficiency of a company. For every company it is vivid to know all that.
From the Bird's Eye View: technical or business innovations impact the day-to-day lives of most individuals e.g., in case of the introduction of newly discovered drugs, that affects the life expectancy of many individuals. But a newly introduced product or service only becomes an innovation after it has been proven in the market - that in fact is the real bottleneck. Today the iterative process of transforming a creation or an invention into an innovation has a tremendous failure rate round about 90% or higher. And no one likes the fact that market failures of products or services are much more common than commercial successes. So innovators face two competing problems at the same time: By ignoring the customers preferences, they can run out of money. And by linking the products too closely to their customers, companies may end up creating only marginal incremental innovations, that have no chance in the market. Therefore it is part of our purpose to help innovators, companies and other startups to dramatically improve their conversion rate, consult management decisions in a data guided way and reduce the failure rate without sacrificing their technical or economic ideas.
Algorithmic Solution: data consisting out of natural numbers, are very frequent. But statistics on integers is notoriously difficult. Hence a reliable statistical analysis of integer data, obtained from online polls aiming to classify the customers properly in order to discover, what selection of their features lead to the same preferences in product features or service features, is hardly available. State of the art (SOTA) in statistics on integers is to fit a parameter dependent, multinomial classification model to the data. As a consequence optimization of the model parameters and model evaluation are the primary concerns of the SOTA-approach, which has so far resisted all attempts at automation. It is well know that already this prevents an algorithmic solution for market research data analysis to be used in any kind of SaaS-type company. This is due to the lack of scalability. Even worse there is no proven recipe to finish the SOTA-approach successfully manualy by a data scientist.
In this situation the algorithmic package that we developed for our client, simplifies the desired grouping of the client's customers according to their votes in integer-based polls in the following way:
- It is a model-free algorithm, that has dropped all geometrical and statistical assumptions, and hence all implicit usage limitations of the former model-based SOTA-approach, that made the statistical analysis of integer data really challenging.
- This new algorithm is fully automated, such that no inspection or iterative improvement by an experienced data scientists is needed to generate an acceptable result by a tailored model. Hence the whhole analysis process becomes easy and fast.
- The new algorithm is a self-learning approach in the sense that all algorithmic parameter, that are needed to complete the procedure and get the result, are computed in a non-parametric way from the data itself.
Project information
- Category Artificial Intelligence
- Client a chain restaurant
- Project date Project started: 01 March, 2022
- Visit Projekt Website
II. Risk-Assessed Financial Forecast
Summary: the success of many B2C-companies depends robust prediction e.g. of future demands and requests including a time dependent risk measure of that prediction, that needs no additional, large training data from the accoutant database.
Keywords: financial predictions, development of cashflow calender, data-driven financial risk mitigation
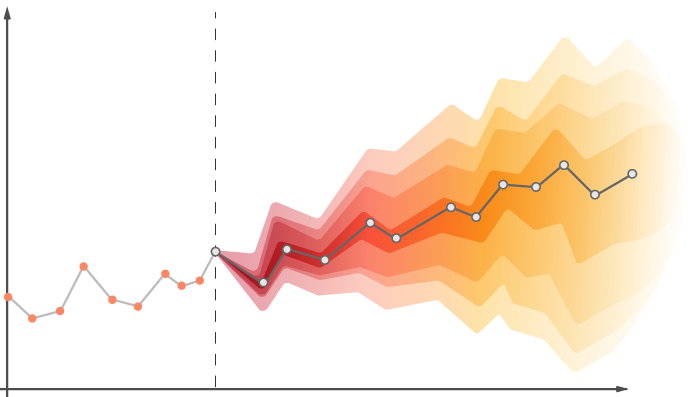
Description: for illustrative purposes of this use case let us think about a Chief Financial Officer (CFO). The main tasks of every CFO is to analyze the cash flow, the liabilities, the financial risks in the market as well as in the company and moreover to ensure that the return on investment is in line with the company targets. To this end the CFO has to recommend effective financial strategies, such that the company can improve its performance. It is well known, that companies are exposed to a wide range of risks from unexpected events and information about these risks can be extracted from the accounting data. But to do this is far from being easy or straightforward:
- Accounting can not always be done by simple continuous real time logging of the business's activity. Instead many financial transactions with customers and business partners are sums of many single transactions. This typically is due to delays in business or bank administration. However umming up accounting data leads to a serious loss of information about the dynamics, the time dependent interplay of a company with their market segments, where they place their products or services.
- Also the same real world processes that correspond to a complex business process has different partial representations in the accounting data. These different accounting data are highly correlated in time, but showing variations in their delays, in their lag times. Hence accounting data can not be considered as realizations of stochastically independent random variables, that are typically used in statistics and machine learning. As a consequence many traditional prediction methods tend to underestimate the business risks. In case of accounting this a serious economic threat.
In this situation accountants have the habit to extract from the data different information needed for different business management purposes e.g. the monthly balances. As a result, information about e.g. an existing dynamic phase in a company's business operations is represented only by a few data points, that can be used as training data for any type of forecasting algorithm. This leads to the notorious problem of few data for machine learningm that can be characterized as follows:
- Since every business and its customers are embedded in constantly changing markets, it can not be expected that any historical time stamped data have some invariant statistical properties in time. This phenomenon is called "non-stationarity". However most prediction methods in AI fail in case of non-stationary data and there is a huge need to find a better algorithm, that can deal with such data.
- Many companies have a complex business dynamics, that consists of diffent components with different types of evolution. The reason for that can be, that they offer different services or follow different revenue models at the same time. If the business dynamics is complex, i.e. an unknown combination of e.g. a non-linear, a stochastic and a periodic component, it is more or less impossible to find a simple, explicit model, that mimics the combined real business development of a that company. Hence prediction methods, using a model, will typically fail in real life scenarios and can not be used for financial risk mitigation.
- Even worse for non-repetitive and simply evolving dynamic processes like the financial state of a business, massive amounts of independent and identically distributed data about the business activities are simply not available. In this case the traditional training of a machine learning model is not possible.
So there is a strong economic need to solve the problem of learning predictions from the temporal correlations in all sorts of historical time stamped and non-repetitive data e.g. accounting data in a automated and model-free way.
From the Bird's Eye View: the main benefit of an algorithmic forecast, meeting the requirements from above, on the one hand is to understand the cost of taking future risks. On the other hand the benefit is to predict the consequences of future decisions in terms of the thereby generated financial risk. The importance of a better risk analysis in case of few data, e.g. short time series, is obvious: The current almost linear increasing complexity of the social and economic phenomena is at least an economic challenge and sometimes a threat for all of us. Hence minimizing the risk of extreme economic or financial events and avoiding to accumulate some hidden risks in the markets will lead to a less chaotic and unpredictable behavior of the markets. That will allow a much more stable cash flow for the companies. In particular the rate of failing startups using risk assessed predictions based on data will drop to the benefit of all of us.
Algorithmic Solution: a time series emerges from every historical time stamped data e.g. from technical sensors or economic measurements. The analysis of time series aims to develop mathematical models to gain an understanding of the underlying causes and driving factors of the temporal development of a business. As a subsequent step predictions about possible non-random future fluctuations and developments of the financial time series can be generated in order to consult strategic decision-making of the management algorithmically. Of course there are some limitations for that, when dealing with the unpredictable or the unknown. Other limitations come from the structural assumption of the used forecast methods itself.
The algorithmic package that we have developed for our client, is self-learning, runs completely automated and computes the prediction and its time dependent risk measure model-free from very few, multivariate data from non-repetitive, but simply evolving processes that typically occur in business of finance.
- The algorithm can finish the task with only one multivariate time series and needs no special training upfront on a statistical large amount of training data. It avoids overfitting and hence computes the probability of extreme events in the underlying dynamical process correctly even in case of the existence of statistical correlations in the data.
- Since sensors and other measurements always represent only some limited perspective on a dynamically developing phenomenon, in most cases many different time stamped data are logged about the same phenomenon. As a consequence the algorithmic prediction method deals with multivariate time series.
- If necessary an automated denoising procedure of the data can be applied before computing the prediction in order to reduce the aleatory uncertainty in the data.
Project information
- Category Artificial Intelligence
- Client a fin-tech startup
- Project date 21 September, 2020
- Visit Projekt Website
III. Logistics
Summary: Planing and scheduling in logistics is a hard problem not only because of the number of tasks, machines, workers or other resources to be handled, but primarily because of the fact that uncertainties and unexpected events can change a schedule locally and may cause catastrophic cascade events, that affect other logistic processes. Hence the crucial point of applying algorithmic solution to logistics is to consider all that uncertainties in planing and scheduling without dropping the efficiency of the delivery processes.
Keywords: scheduling of workforce and logistic resources, planing of logistic processes including managment of internal risks
Description: delivery processes are determined by a lot of categorial factors e.g. the choice of the team and the truck, the features of the destination or the sequence of used roads. Also non-categorial factors e.g. the distance, the starting time or the load itself are important. The incluence on the expected time of availability (ETA) is easy to measure in case of the non-categorial factors. However the understanding of the influence of the categorial features is hard to measure and in most cases only based on unreliable practical experience. Hence the lack of understanding of logistic processes has two sides:
- The strength of the influence of every single non-categorial factor is hard to estimate with numerical methods. The same is true with the range of that influence over a sequence of steps in a complex delivery process.
- The network of causal relations between categorial factor and non-categorial factors is unknown. But obviously this lacking knowledge plays a central role for the ETA of a truck or a team. So having more insight would on the one hand allow to increase the frequency of delivery processes and on the other hand to minimize the amount of company resources that are used to keep the business running.
Recall that each logistics company pursues at least two main goals: to have lean delivery or supply processes and to minimize expenses, since the prize pressure on logistics - in particular on intra-logistics - is nearly unlimited. Neither of these goals can be achieved without a data-based analysis of the complex logistic processes and the control over all resources - including transparent process planning for customers. Planing and scheduling also have to take into account that the two main goals are conflicting for every single delivery and are constrained by the inherent local variations in the categorial factor and non-categorial factors determining the uncertainties of the ETA.
From the Bird's Eye View: logistics companies are made to enable a thriving economy and they are constantly faced with two challenges. On the one hand, they want to follow their customers' demands for price reductions, as they actually only see logistics as a cost factor. On the other hand, they want to adapt to the current needs of customers, who have also updated their products and services on the basis of data-driven CRM, for example. Under these conditions, in-house investments are only possible if the compromise between lean and robust logistics processes is continuously readjusted. This task requires data-driven optimisational solutions that can be calculated quickly, which only carry out the unavoidable reactions to unforeseen events, eliminate unnecessary waiting times and prevent cascading events.
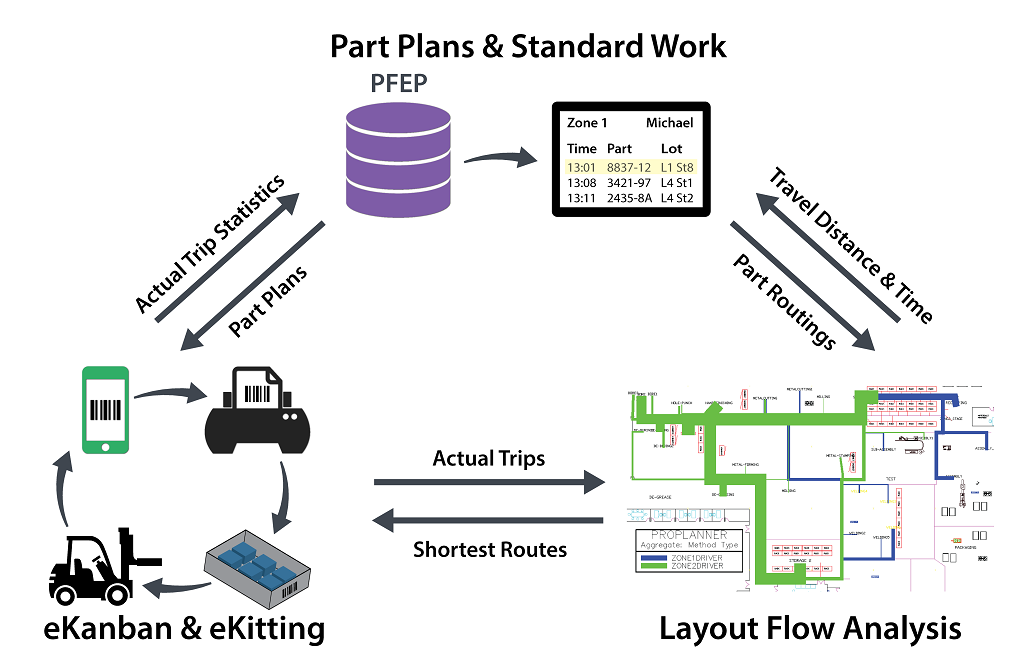
Algorithmic Solution: our entire algorithmic solution is based on the quantitative understanding of the flow of uncertainty along the various stations or stops in the delivery process - both in terms of the strength and in terms of the causal dependencies between the categorial and non-categorial factors influencing the ETA of a logistic resource.
The algorithmic package that we have developed for our client, is supervized, but scheduled in a cycle of a few minutes, such that new emerging updates about the states of the logistic processes can be considered in the optimal rescheduling procedure of all available logistic resources. The effect of our algorithmic solution is threefold:
- The computed causal relationships between various categorical and non-categorical factors make it possible to identify the extent of the adjustments that have become necessary in all logistical processes.
- The computed strength of the causal influence of the various categorical and non-categorical factors on the logistic processes is used to estimate the final effects of unexpected distortions on the ETA. This partial result allows to rearrange subsequent logistic processes in time in an optimal way.
- The computation of the optimal rescheduling allows to set priorities either to the side of the robustness or to the leanness and efficiency of the affected logistic processes - depending on the requirements of the business.
Additional hard constraints coming from the customers of the logistic companies or from the organisational side of the workforce can be added manualy at some time point or scheduled to one of the cycles of the rescheduling. A certain amount of work by data scientists for checks and adaptations is unavoidable.
Project information
- Category Artificial Intelligence
- Client a large logistic company
- Project date 01 November, 2023
- Visit Projekt Website